Understanding data mining clustering methods Subconscious Musings
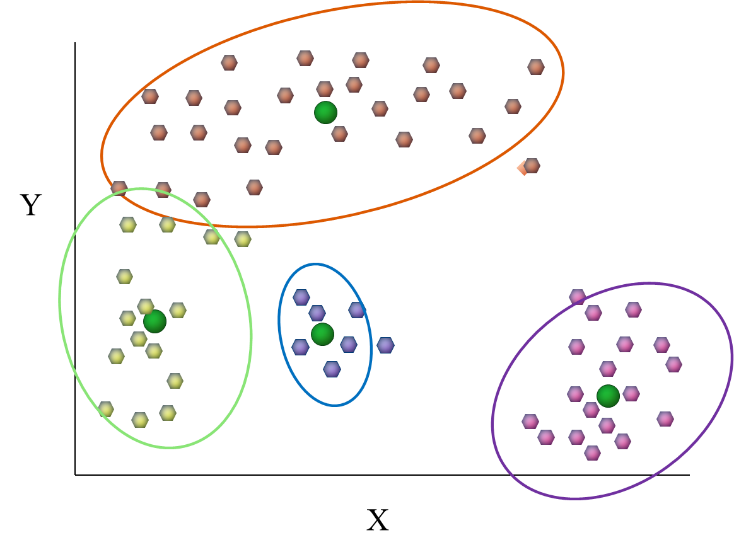
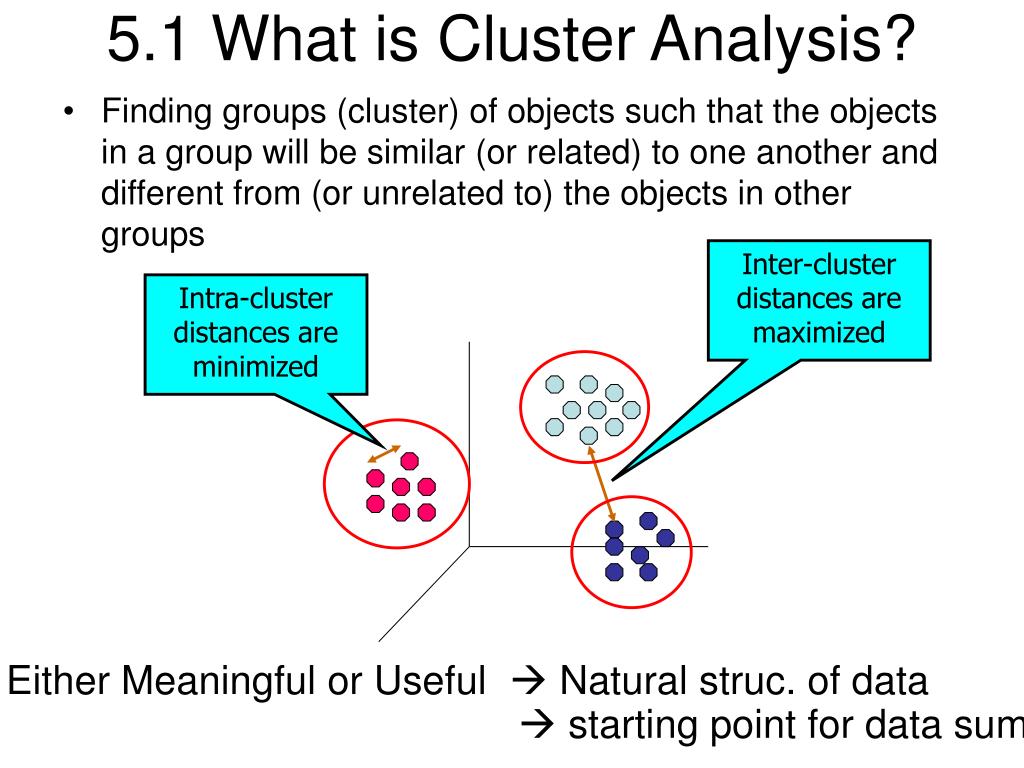
INTRODUCTION: Cluster analysis, also known as clustering, is a method of data mining that groups similar data points together. The goal of cluster analysis is to divide a dataset into groups (or clusters) such that the data points within each group are more similar to each other than to data points in other groups.
Data Mining Cluster Analysis Javatpoint
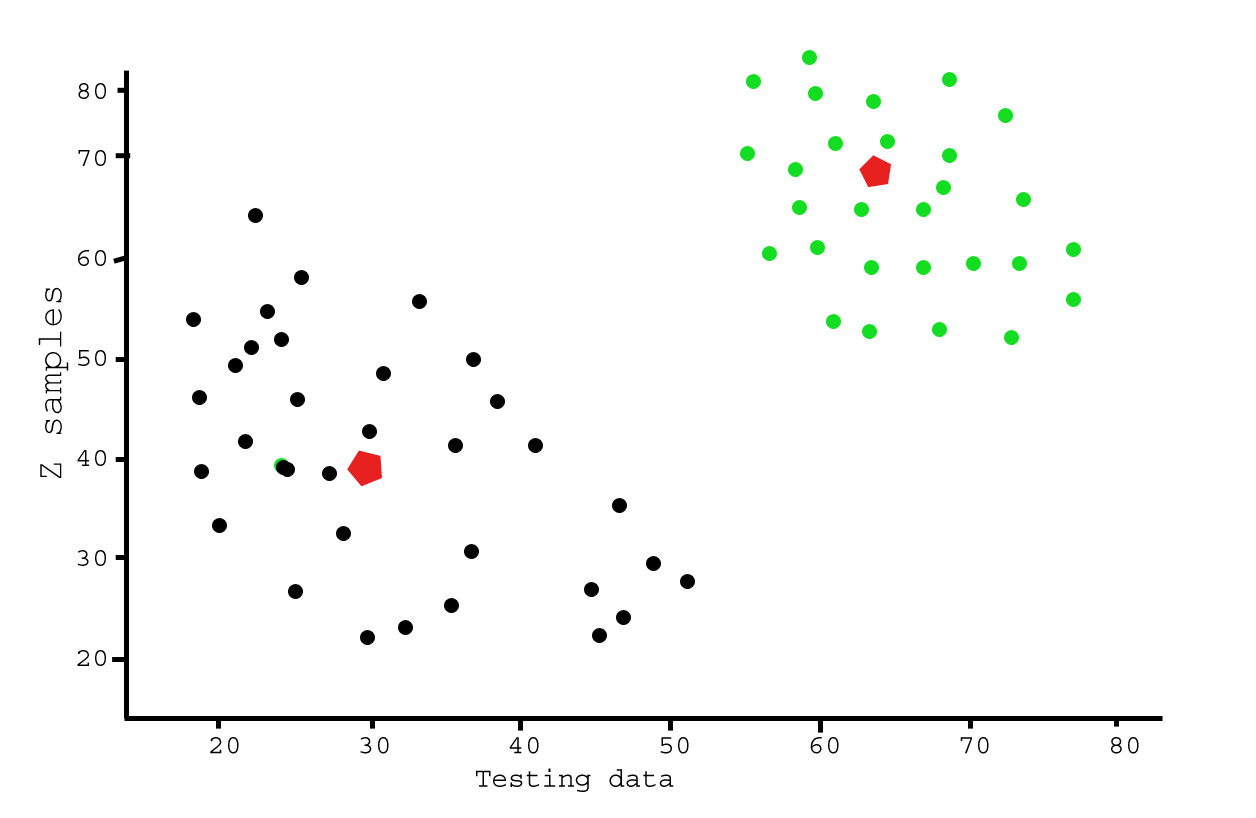
Centroid-based clustering organizes the data into non-hierarchical clusters, in contrast to hierarchical clustering defined below. k-means is the most widely-used centroid-based clustering algorithm. Centroid-based algorithms are efficient but sensitive to initial conditions and outliers. This course focuses on k-means because it is an.
Orange Data Mining Hierarchical Clustering
Cluster analysis, also known as clustering, is a statistical technique used in machine learning and data mining that involves the grouping of objects or points in such a way that objects in the same group, also known as a cluster, are more similar to each other than to those in other groups. It is a main task of exploratory data analysis and is.
Measuring Clustering Quality in Data Mining
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some specific sense defined by the analyst) to each other than to those in other groups (clusters). It is a main task of exploratory data analysis, and a common technique for statistical data analysis, used in many fields, including.

Clustering in Data Mining Data Mining Tutorial wikitechy
Abstract. Research on the problem of clustering tends to be fragmented across the pattern recognition, database, data mining, and machine learning communities. Addressing this problem in a unified way, Data Clustering: Algorithms and Applications provides complete coverage of the entire area of clustering, from basic methods to more refined and.

Clustering in Data mining K means Clustering Algorithm Hierarchical
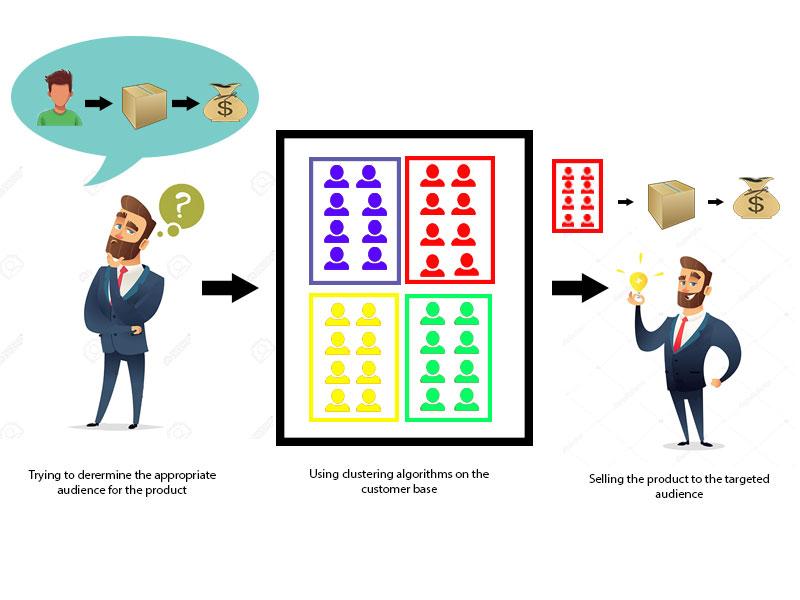
Clustering in data mining is a technique used to group similar data points together based on their features and characteristics. It is an unsupervised learning method that helps to identify patterns in large datasets and segment them into smaller groups or subsets. Clustering can be used for various applications such as customer segmentation.

Review on Clustering Techniques in Data Mining 2016 YouTube
Summary. Cluster analysis is a powerful technique for grouping data points based on their similarities and differences. In this guide, we explore the top data mining tools for cluster analysis, including K-means, Hierarchical clustering, and more. We look at an overview of the benefits and applications of cluster analysis in various industries.
PPT Data Mining Cluster Analysis Basic Concepts and Algorithms
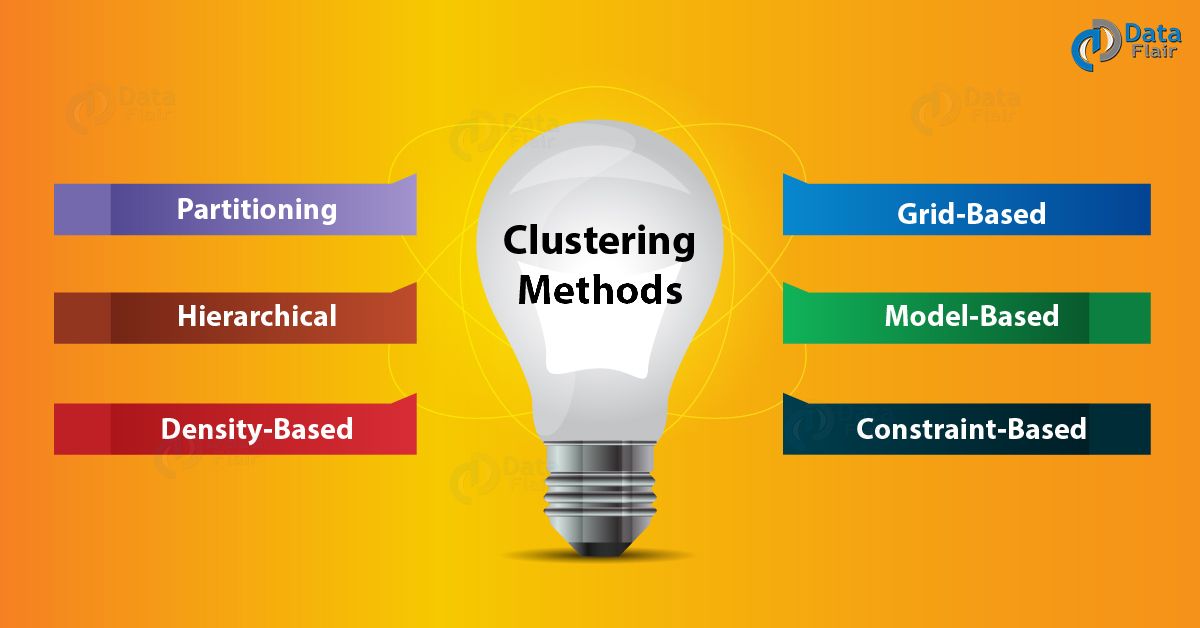
In data mining, Clustering is the most popular, powerful and commonly used unsupervised learning technique. It is a way of locating similar data objects into clusters based on some similarity. Clustering algorithms can be categorized into seven groups, namely Hierarchical clustering algorithm, Density-based clustering algorithm, Partitioning clustering algorithm, Graph-based algorithm, Grid.

Clustering in Data Mining Algorithms of Cluster Analysis in Data
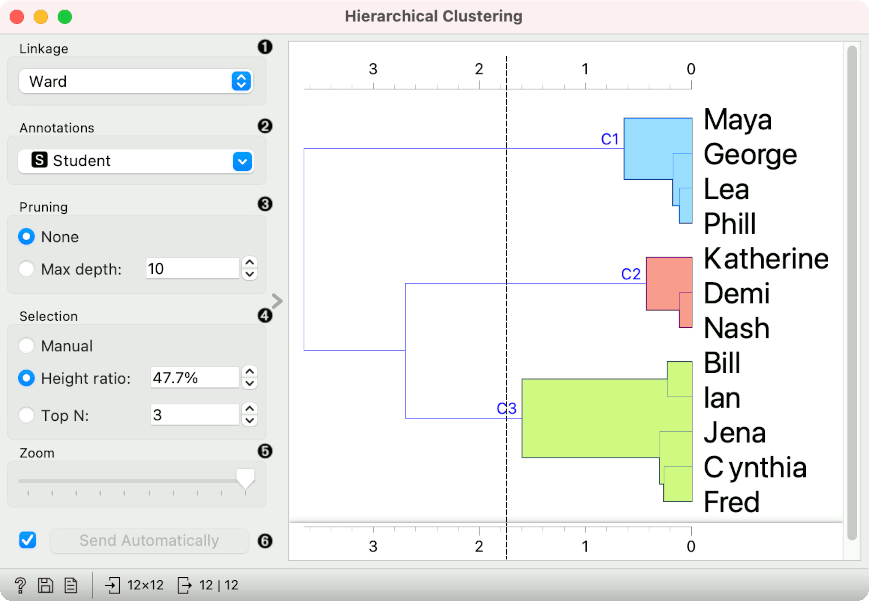
1) Clustering Data Mining Techniques: Agglomerative Hierarchical Clustering. There are two types of Clustering Algorithms: Bottom-up and Top-down. Bottom-up algorithms regard data points as a single cluster until agglomeration units clustered pairs into a single cluster of data points. A dendrogram or tree of network clustering is employed in.

The 5 Clustering Algorithms Data Scientists Need to Know
Requirements of clustering in data mining: The following are some points why clustering is important in data mining. Scalability - we require highly scalable clustering algorithms to work with large databases. Ability to deal with different kinds of attributes - Algorithms should be able to work with the type of data such as categorical.
Analytics and Visualization of Big Data Distancebased clusterings
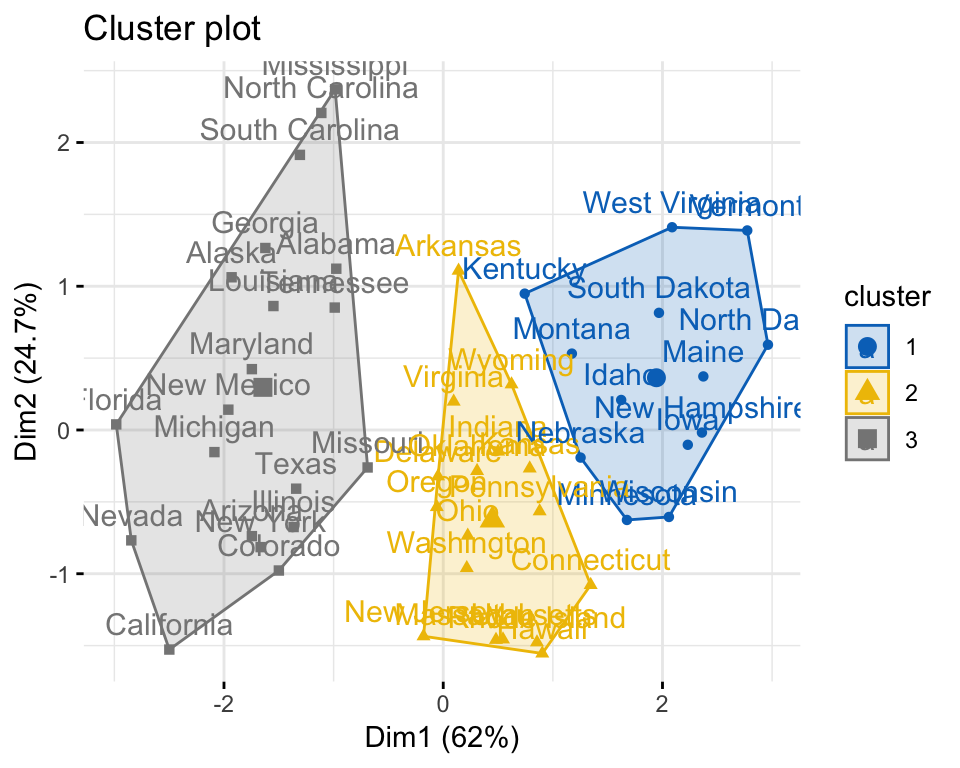
Cluster analysis is a data analysis method that clusters (or groups) objects that are closely associated within a given data set. When performing cluster analysis, we assign characteristics (or properties) to each group. Then we create what we call clusters based on those shared properties. Thus, clustering is a process that organizes items.
Clustering in Data Mining Algorithms of Cluster Analysis in Data
A cluster of data objects can be treated as one group. While doing cluster analysis, we first partition the set of data into groups based on data similarity and then assign the labels to the groups. The main advantage of clustering over classification is that, it is adaptable to changes and helps single out useful features that distinguish.
Data Analytics TYPES OF CLUSTERING METHODS OVERVIEW AND QUICK START
13 videos • Total 65 minutes. 1.1. What is Cluster Analysis • 2 minutes • Preview module. 1.2. Applications of Cluster Analysis • 2 minutes. 1.3 Requirements and Challenges • 5 minutes. 1.4 A Multi-Dimensional Categorization • 2 minutes. 1.5 An Overview of Typical Clustering Methodologies • 6 minutes.
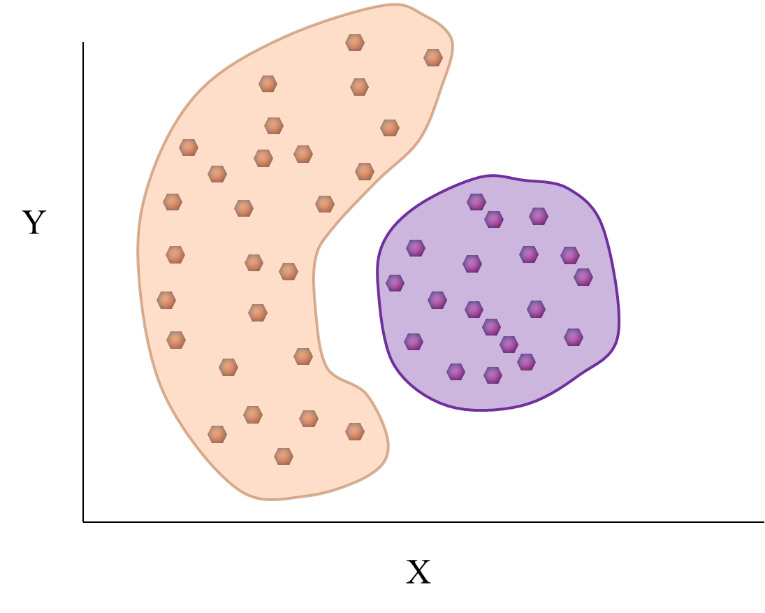
Understanding data mining clustering methods The SAS Data Science Blog
Machine learning systems can then use cluster IDs to simplify the processing of large datasets. Thus, clustering's output serves as feature data for downstream ML systems. At Google, clustering is used for generalization, data compression, and privacy preservation in products such as YouTube videos, Play apps, and Music tracks.
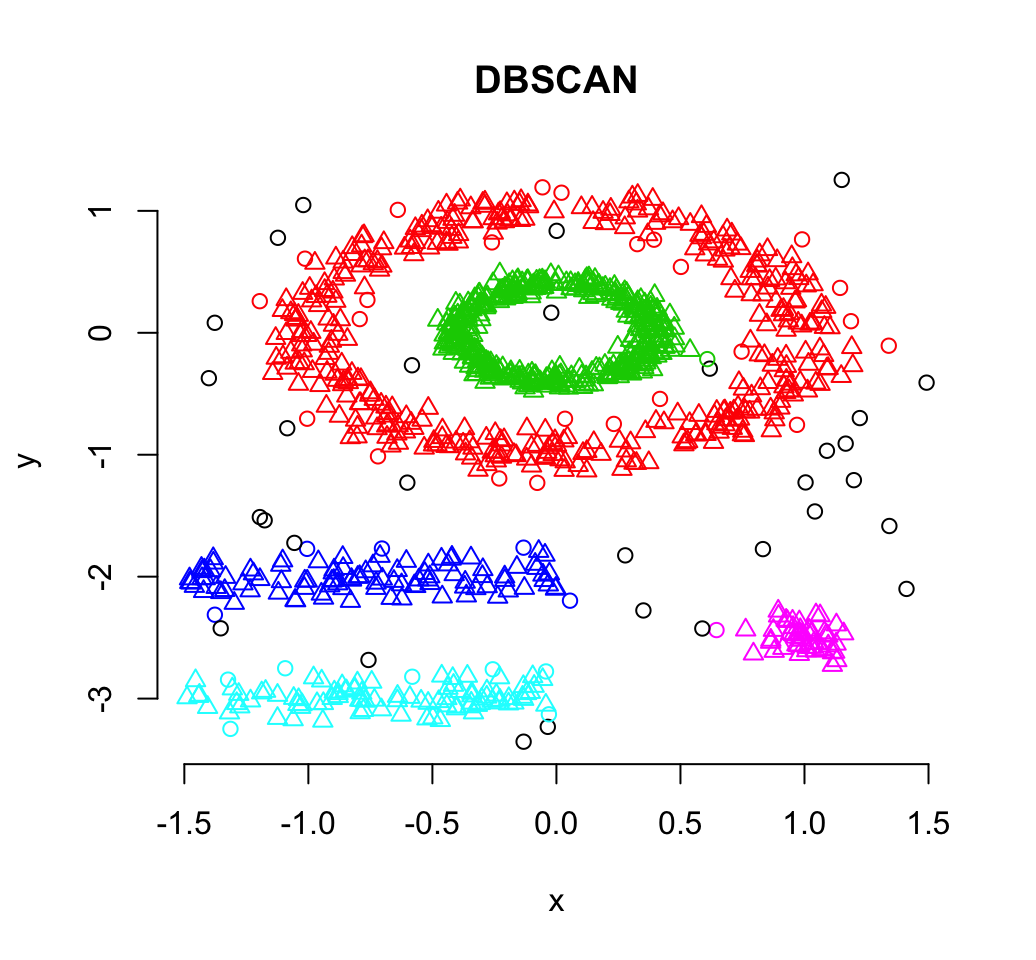
Types of Clustering 5 Awesome Types of Clustering You Should Know
Methods of Clustering in Data Mining. The different methods of clustering in data mining are as explained below: 1. Partitioning based Method. The partition algorithm divides data into many subsets. Let's assume the partitioning algorithm builds a partition of data and n objects present in the database.

Clustering Algorithms in Data Mining Meaning DataTrained Data
Abstract. Data Mining is the procedure of extracting information from a data set and transforms information into comprehensible structure for processing. Clustering is data mining technique used to process data elements into their related groups or partition. Thus, the process of partitioning data objects into subclasses is term as 'cluster'.